What's in the bag? Behind the scenes at vBrownBag.com
- What’s in the bag? Behind the scenes at vBrownBag.com
- Part 2 of “What’s in the bag?” Behind the scenes at vBrownBag.com
- Part 3 of “What’s in the bag?” Behind the scenes at vBrownBag.com
- Part 4 of “What’s in the bag?” Behind the scenes at vBrownBag.com
- Part 5 of “What’s in the bag?” Behind the scenes at vBrownBag.com
- Part 6 of “What’s in the bag?” Behind the scenes at vBrownBag.com
- Automating the vBrownBag with AWS Serverless
In Part 3 of this series, I covered the development environment & tools. In this installment, I’d like to show you how I’ve decided to orchestrate the workflow around the Lambda function. You may also want to review the overall process in Part 2, as I’ll be referring to how I decided to implement the process on AWS.
One of this function’s primary design goals was for it to be entirely event-driven. I didn’t want to be concerned with giving future friends of the vBrownBag access to invoking the Lambda function directly, or to be concerned with any other details than simply uploading a video file along with a metadata file. However, I couldn’t quite figure out a graceful way to make sure both the .mp4 & .csv files were present before moving forward with the automation process. If you’ve dealt with AWS, you’re probably well aware that there are many different ways to solve a problem. That’s the benefits of AWS’ focus on cloud primitives (vs a cloud like Azure that tends to focus more on solutions). Here’s a few examples: 1.) I could’ve simply triggered the Lambda function from an S3 PUT and then let Lambda exit if both files weren’t present, but that would’ve introduced unnecessary Lambda executions that would’ve been unsuccessful half the time. 2.) I could’ve allowed a human to invoke the function directly, after uploading both files. This wasn’t a bad idea, but still required more interaction than I wanted. 3.) I could’ve had Lambda run regularly to check for new files in an S3 bucket, but that’s a clumsier approach. Honestly, the list could go on and on. I finally decided to build an AWS EventBridge rule that would start a Step Functions state machine execution after a .csv file is uploaded to an S3 bucket. As these notifications happen in millisecond time frames, the first thing Step Functions does is wait before asking the Lambda function to check if both files are present. Ultimately, I decided that being event-driven doesn’t mean that event responses have to happen immediately, as there’s no point in having millisecond responses to find files that aren’t done uploading.
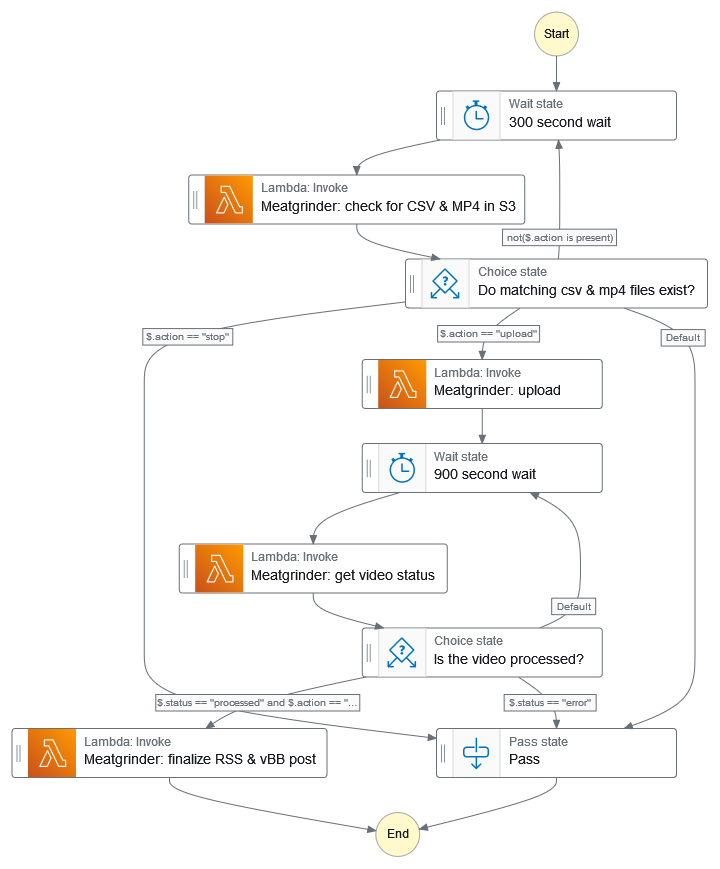
As you can see in the graph, there’s an initial 5 minute wait to allow for large .mp4 files to finish uploading. After that, the Lambda function is invoked to check for matching .mp4 & .csv files in a private S3 bucket. If they exist, JSON is returned to the state machine indicating that the process can move forward. If not, then JSON is returned that it’s still waiting. This loop eventually breaks out and exits after running a few times, just to make sure that this doesn’t run indefinitely during an incomplete upload. Each JSON output is interpreted and acted upon by the Lambda function, which also constructs JSON responses to the state machine upon completion.
Here’s example JSON that EventBridge sends to Step Functions (using InputPath filtering on $.detail.object). Step Functions invokes the Lambda function with the JSON as input. Inside the Lambda function, the input is received as $LambdaInput which is a PSObject that contains input to the function’s configured handler method.
{
"key": "test2-long.csv",
"size": 644,
"etag": "26f04fed485a8b0487b17974b313b52d",
"version-id": "w9ywc77rdDz49dYmUPRRTEVzcQqAifIM",
"sequencer": "00663D74124FC29E94"
}The Meatgrinder Lambda function processes this input, checks to see if a matching .mp4 file exists, and then responds with JSON to the Step Function state machine. All of the JSON returned by the function is built as a PSCustomObject and then converted to JSON using ConvertTo-JSON.
{
"action": "upload",
"video": {
"name": "test2-long.mp4",
"privacyStatus": "public",
"csv": "test2-long.csv"
}
}Meatgrinder refreshes the OAuth token used to authenticate to our YouTube channel, builds a Google.Apis.YouTube.v3.Data.Video object containing information about the video, uploads to YouTube, and then copies the .mp4 from the S3 working bucket over to our public bucket named as videoId.mp4, which reflects the unique ID that YouTube assigned the upload. At this point in the process, the YouTube data API is the source of truth for publish times, content duration, thumbnail images, etc. so an OAuth authenticated Google.Apis.YouTube.v3.Data.VideoListResponse object is converted to JSON and saved in the working bucket.
An additional wait period is introduced to wait on the YouTube data API to signal that the video is done processing. As there’s no exponential backoff in Step Functions, I chose a wait period of 15 minutes, as an hour of HD video may take 20-30 minutes to process. Once the API says the video has been processed, Meatgrinder is invoked again to finish the vBrownBag.com blog post & Apple Podcasts RSS update.
{
"action": "finalize",
"video": {
"id": "ZshoNZd2-_g"
},
"status": "processed"
}I spent some time trying to figure out how to make sure that the function was idempotent, as I didn’t want to accidentally duplicate vBrownBag.com blog posts or RSS entries. I solved this by appending a wpPost_Id key/value pair in the JSON which won’t trigger a new blog post if the value isn’t null (meaning, a blog post with that id exists). Additionally, by using the YouTube videoId as a unique identifier, I’m able to find any XML entries that match that videoId and not add a new one if it already exists.
Lambda function internal structure
In addition to the handler() function itself, the rest of the Meatgrinder Lambda function consists of PowerShell functions that are named like PowerShell cmdlets with approved verbs such as New-YouTubeVideo, Get-OAuthRefresh, Update-RSS, etc. I also wrote extensive comment-based help for the PowerShell functions. Parameters are defined (string, object, etc), consistently named, and enforced when passed between other PowerShell functions. I’ve also tried to consistently use try/catch blocks for error handling, and logging Meatgrinder process steps to AWS CloudWatch using PowerShell’s Write-Host. These were intentional choices designed to document the code and to make it easier to understand for future maintainers (or myself, in 6 months!)
Stay tuned for Part 5, where I’ll cover Google OAuth & PSAuthClient, decrypting AWS Lambda environment variables, and more. Thanks for reading!